Redshift
Overview
- for OLAP, not OLTP
- multi-terabyte clusters in minutes
- column-oriented
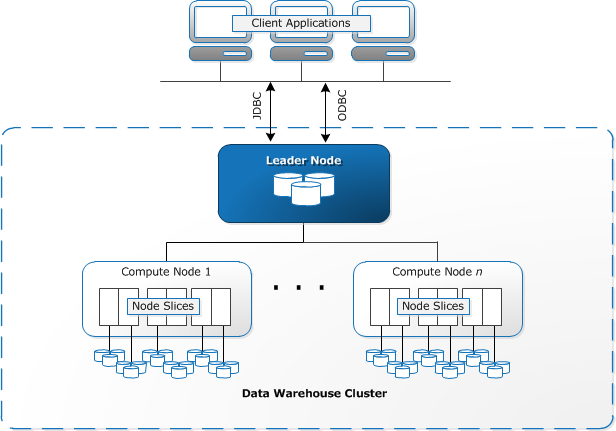
Redshift architecture
- 1 leader node, multiple compute nodes
- Leader node
- has the SQL endpoint
- coordinates parallel query execution
- Compute node
- queries are executed in parallel in multiple nodes
- scale out / up/ down
- 10 GBe network
- Leader node
- runs in a single AZ (high-speed network communication)
- instance types: dc2 (dense compute), and dense storage (ds2)
- data stored on multiple nodes, dedicated CPU, memory and local storage
- Columnar data store:
- tables are stored as columns not rows, so reading single or few columns is much faster
- do not use for small amount of data, binary large objects, OLTP
Redshift integrations in AWS:
- COPY command
- to load data from:
- S3,
- DynamoDB
- includes reference to IAM role
- to load data from:
- skipped others..
Table Design
- Distribution styles
- Even (default)
- rows distributed accross slices regardless of values in a particular column
- Key
- Used to optimize JOINs. same key should be in the same slice to be faster.
- All
- copy of entire table is in each table
- use case: data that does not change. not large tables.
- Even (default)
- Sort Keys
- Similar to indexes. They are not indexes.
- Redshift uses block size of 1MB. Less IO seeks
- Sort order allows quicker reading.
- compound (default):
- includes all columns stated. Order matters (sames as mysql indexes). Must include prefix of columns (same order).
- vacuum and analyze operations used for improving performance
- interleaved:
- all columns are equally important.
- Data load and vacuum is slower
- Use on very large tables
- Not good for loading data in sort order
- Compression:
- compound (default):
- ENCODE lzo, mostly32, etc. reduce size
- redshift support automatic compression
- redshift automatically figures out a good encoding
- runs ANALYZE command behind the scenes on table creation (only first time)
- manual compression
- run ANALIZE compression table_name, which suggests compression
- constraint
- run ANALIZE compression table_name, which suggests compression
- column-level:
- PRIMARY KEY
- UNIQUE (it's not enforceable by redshift)
- NOT NULL / NULL (the only that is enforced)
- REFERENCES (same as FK), not enforceable by redshift
- use only if the application enforces the constraints prior to data ingestion (helps with query planning, improving performance)
- table_inspector util can be used to list what tables have nconding, sort keys, etc.
Redshift Workload management:
- rules to route queries (to manage slow / fast queries)
- define allocation of % of memory for specific user groups or query groups.
- creating user groups and query groups reqiures cluster reboot
- dont require reboot:
- changing memory % per user group / query group
- also concurrency (how many concurrent queries)
- also timeout
- Can't explicitly prioritize queries, but use queues instead.
Loading data to redshift:
- don't use single inserts, use COPY command:
- from S3, dynamoDB, EMR, EC2
- split files (use same prefix), and copy will load in parallel, faster
- services that need to go through S3:
- Kinesis firehose
- kinesis app
- AWS DB Migration Service
- Can use lambda to run the copy command triggered on S3.
- Splitting files
- use number of files = number of slices or a multiple e.g. 4 slices -> 4, 8, 12, .. files
- keep file sizes even
- Compress files (gzip, bzip, ...)
- Keep files between 1MB to 1GB
- when reading from dynamodb
- specify readratio (a percentage of total RCU)
- or use a copy of the table
- manifest:
- a way to specify which files should be loaded, and from where.
- manifest file is in JSON format, usually stored in S3
- useful for:
load required files only
- load files from different buckets
- load files with different prefixes
- Support file format:
- CSV, delimited, JSON, fixed width, Avro
- When copy command fails, check tables
STL_LOAD_ERRORS,STL_LOADERROR_DETAIL - Redshift does not support UPSERT. Methods:
- Staging table
- use staging table. Replace all table in target table or merge all of them into target table.
- target and staging table columns must match
- within a transaction:
- delete from target table rows from staging table.
- insert into target table from staging table
- within a transaction:
- create a stanging table, update target table from staging table.
- drop staging table
- Staging table
- Can use encryption with the COPY command.
- Not supported:
- servier side with customer provided keys
- clioent side encryption with KMS
- client side assymetric master key
- Not supported:
- Unloading query results to S3, use UNLOAD command,
- using S3 server side encryption by default (SSE-s3).
- Can also use server side SSE-KMS
- can use client side customer managed key (CSW-CMK)
- not supported:
- S3 encryption with server side customer supplied key
Maintenance operations
- Resize process
- cluster goes into read-only mode, running queries and connections are terminated
- cluster is restarted
- queries in read-only mode in source cluster
- target cluster is populated, DNS points to new cluster
- source cluster is terminated
- Redshift blocks are immutable. Need to vacuum operation for resorting and remove unused disk space.
- vacuum is io intensive, use during lower use periods / maintenance windows
- use redshift utility analyze_and_vacuum_utility to figure out what tables should be vacuumed
- avoid vacuum by Loading data in sort order, and using timeseries tables
- avoid vacuum on large tables (>700GB), recreate a nd repopulate table with bulk insert
- Can set up cross region snapshot (can use KMS encrypted snapshots)
- KMS encrypted creates a nsapshot copy grant in the destination region
- restoring from snapshot is straightforward (same cluster size, etc)
- can restore single table from snapshot as well.
- Monitoring: use cloudwatch
Amazon Machine Learning
- skipped several details ..
- point to an s3 file with the input dataset (e.g: csv)
- define what are the output features
- ML automatically detects type
- ML can choose the type of data automatically (multiclass, ..)
- Default split is 70% training , 30% test
Can set the score threshold for binary classification
check the grant thingie (where was this from?)
AWS Redshift
- Amazon Redshift is a fully managed, fast and powerful, petabyte scale data warehouse service
- Redshift automatically helps
- set up, operate, and scale a data warehouse, from provisioning the infrastructure capacity
- patches and backs up the data warehouse, storing the backups for a user-defined retention period
- monitors the nodes and drives to help recovery from failures
- significantly lowers the cost of a data warehouse, but also makes it easy to analyze large amounts of data very quickly
- provide fast querying capabilities over structured data using familiar SQL-based clients and business intelligence (BI) tools using standard ODBC and JDBC connections.
- uses replication and continuous backups to enhance availability and improve data durability and can automatically recover from node and component failures.
- scale up or down with a few clicks in the AWS Management Console or with a single API call
- distribute & parallelize queries across multiple physical resources
- supports VPC, SSL, AES-256 encryption and Hardware Security Modules (HSMs) to protect the data in transit and at rest.
- Redshift only supports Single-AZ deployments and the nodes are available within the same AZ, if the AZ supports Redshift clusters
- Redshift provides monitoring using CloudWatch and metrics for compute utilization, storage utilization, and read/write traffic to the cluster are available with the ability to add user-defined custom metrics
- Redshift provides Audit logging and AWS CloudTrail integration
- Redshift can be easily enabled to a second region for disaster recovery.

Redshift Performance
- Massively Parallel Processing (MPP)
- automatically distributes data and query load across all nodes.
- makes it easy to add nodes to the data warehouse and enables fast query performance as the data warehouse grows.
- Columnar Data Storage
- organizes the data by column, as column-based systems are ideal for data warehousing and analytics, where queries often involve aggregates performed over large data sets
- columnar data is stored sequentially on the storage media, and require far fewer I/Os, greatly improving query performance
- Advance Compression
- Columnar data stores can be compressed much more than row-based data stores because similar data is stored sequentially on disk.
- employs multiple compression techniques and can often achieve significant compression relative to traditional relational data stores.
- doesn’t require indexes or materialized views and so uses less space than traditional relational database systems.
- automatically samples the data and selects the most appropriate compression scheme, when the data is loaded into an empty table
Redshift Single vs Multi-Node Cluster
- Single Node
- single node configuration enables getting started quickly and cost-effectively & scale up to a multi-node configuration as the needs grow
- Multi-Node
- Multi-node configuration requires a leader node that manages client connections and receives queries, and two or more compute nodes that store data and perform queries and computations.
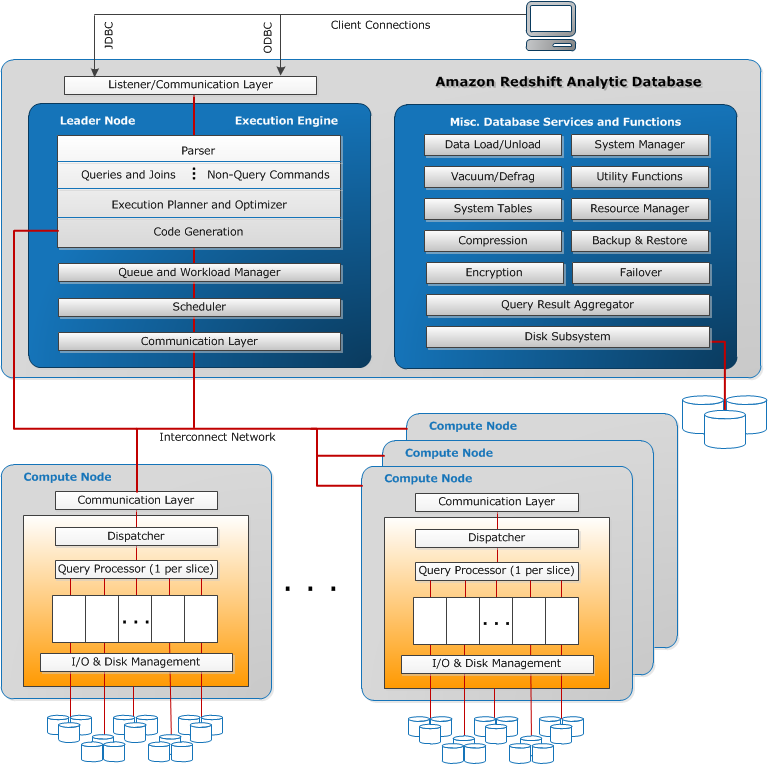
- Leader node
- provisioned automatically and not charged for
- receives queries from client applications, parses the queries and develops execution plans, which are an ordered set of steps to process these queries.
- coordinates the parallel execution of these plans with the compute nodes, aggregates the intermediate results from these nodes and finally returns the results back to the client applications.
- Compute node
- can contain from 1-128 compute nodes, depending on the node type
- executes the steps specified in the execution plans and transmit data among themselves to serve these queries.
- intermediate results are sent back to the leader node for aggregation before being sent back to the client applications.
- supports Dense Storage or Dense Compute nodes (DC) instance type
- Dense Storage (DS) allow creation of very large data warehouses using hard disk drives (HDDs) for a very low price point
- Dense Compute (DC) allow creation of very high performance data warehouses using fast CPUs, large amounts of RAM and solid-state disks (SSDs)
- direct access to compute nodes is not allowed
Redshift Availability & Durability
- Redshift replicates the data within the data warehouse cluster and continuously backs up the data to S3 (11 9’s durability)
- Redshift mirrors each drive’s data to other nodes within the cluster.
- Redshift will automatically detect and replace a failed drive or node
- If a drive fails, Redshift
- cluster will remain available in the event of a drive failure
- the queries will continue with a slight latency increase while Redshift rebuilds the drive from replica of the data on that drive which is stored on other drives within that node
- single node clusters do not support data replication and the cluster needs to be restored from snapshot on S3
- In case of node failure(s), Redshift
- automatically provisions new node(s) and begins restoring data from other drives within the cluster or from S3
- prioritizes restoring the most frequently queried data so the most frequently executed queries will become performant quickly
- cluster will be unavailable for queries and updates until a replacement node is provisioned and added to the cluster
- In case of Redshift cluster AZ goes down, Redshift
- cluster is unavailable until power and network access to the AZ are restored
- cluster’s data is preserved and can be used once AZ becomes available
- cluster can be restored from any existing snapshots to a new AZ within the same region
Redshift Backup & Restore
- Redshift replicates all the data within the data warehouse cluster when it is loaded and also continuously backs up the data to S3
- Redshift always attempts to maintain at least three copies of the data
- Redshift enables automated backups of the data warehouse cluster with a 1-day retention period, by default, which can be extended to max 35 days
- Automated backups can be turned off by setting the retention period as 0
- Redshift can also asynchronously replicate the snapshots to S3 in another region for disaster recovery
Redshift Scalability
- Redshift allows scaling of the cluster either by
- increasing the node instance type (Vertical scaling)
- increasing the number of nodes (Horizontal scaling)
- Redshift scaling changes are usually applied during the maintenance window or can be applied immediately
- Redshift scaling process
- existing cluster remains available for read operations only while a new data warehouse cluster gets created during scaling operations
- data from the compute nodes in the existing data warehouse cluster is moved in parallel to the compute nodes in the new cluster
- when the new data warehouse cluster is ready, the existing cluster will be temporarily unavailable while the canonical name record of the existing cluster is flipped to point to the new data warehouse cluster
Redshift vs EMR vs RDS
- RDS is ideal for
- structured data and running traditional relational databases while offloading database administration
- for online-transaction processing (OLTP) and for reporting and analysis
- Redshift is ideal for
- large volumes of structured data that needs to be persisted and queried using standard SQL and existing BI tools
- analytic and reporting workloads against very large data sets by harnessing the scale and resources of multiple nodes and using a variety of optimizations to provide improvements over RDS
- preventing reporting and analytic processing from interfering with the performance of the OLTP workload
- EMR is ideal for
- processing and transforming unstructured or semi-structured data to bring in to Amazon Redshift and
- for data sets that are relatively transitory, not stored for long-term use.