绪论
什么是深度学习
简单的说明这本书是一本入门的书籍,跳过不想关的内容,直接进入深度学习的发展趋势。附上使用的连接 www. deeplearningbook.org.这里可以查看目录连接这本书的主要目的是去解决这种更加需要直觉的问题。解决这样的一个问题就可以使得计算机从经验中学习并且从层级的概念上去理解这个世界。层级的概念使得计算机可以用简单的概念去学习复杂的概念。如果采用一个graph来描述这些概念是怎么在彼此的上面构成的,这样的graph就是deep的,所以就把这种方式称为了 AI Deep Learning。计算机想要智能的方式就是需要找到一个方式将这种normal的知识转换到计算机当中去。 有几个人工智能项目想采用硬编码的方式来实现(硬编码是指将可变变量用一个固定值来代替的方法)但是都没有成功。这种方式通常被称为通向人工智能的knowledge base方式。著名的项目之一就是Cyc。但是这样的失败是有意的,通过这些尝试,人们认为AI需要通过从raw data提取模式从而获得它自己的知识,所以有了Machine Learning。最简单的机器学习方法之一就是逻辑回归(logistics regression)用来判断是否建议剖腹产,而naive Bayes(朴素贝叶斯方法)可以用来区分正常邮件和垃圾邮件。 简单的机器学习算法很大程度上依赖与所给数据的表述能力(representation),例如上述的逻辑回归例子,并不能直接用于病人的检测,而是需要依靠doctor所给出的数据。这个表述当中所包含的信息块就被称作为feature(特征)。逻辑回归就是学习这些feature和各种输出之间的相关性,但是它不能影响features的定义(Mu:也就是说这个方法不能自主的选择合适的特征)。客观的说,很多的问题都可以通过设计合适的特征来完成。 但是(说道但是,对吧,就到核心了,也即是为什么会有DL,也就说明了DL的特点是什么)对于很多任务来讲,我们并不知道设计怎样的特征算是好的合适的特征。解决这个问题的方法就是找到一中机器学习算法,这个方法不仅能发现映射表述到输出,同时能够发现表述本身,这个方式就被称为representation learning(学习)。学习到的特征一般比手动设计的特征具有更好的效果。那么关于这种表述学习的一个比较好的例子就是autoencoder(计算机自动编码,encoder+decoder)。 在设计学习特征的特征以及算法的时候,我们的目标是将描述观测数据的变量因素(factor of variation)分开,采用factores来描述不同因素的影响。真实世界的人工智能的主要困难应用之处在于很多的变量因素会影响到我们观测数据的每一个片信息(piece of data)。DL解决这个问题的方式就是就是采用其他更加简单的representations来表示,当然这个是由Dl学习所得到的,下图是一个典型的图像识别深度网络结构,DL在这个方面就是将一个复杂的mapping划分称为一系列嵌套的简单映射(nested simple mappings),每个都可以模型的不同层来进行表示。深度网络的典型结构例子就是前馈深度网络(deep network)或者称为多层感知器(multilayer perceptron,MLP)(概念:Depth is the length of the longest path from input tooutput but depends on the definition of what constitutes a possible computational step)Figure 1
有两种方式来衡量模型的深度:第一种就是sequential instructions的数目,我们可以把这个想象成最长的计算路径;另一种方式就是描述概念之间相互关系的网络深度,但是这个方式呢要计算需要计算每个concept的representation,所以会比graph的深度要深,主要是因为简单的概念能被定义,从而能够表述更加复杂的概念。
深度学习的历史
- 深度学习有着长而丰富的开始,曾经有过很多的名字,作为深度学习受到了普遍的接收和欢迎
- 因为训练数据的增加导致了深度学习越来越有用
- 随着计算机技术的增长,深度学习模型规模也越来越大
- 随着时间的推移,深度学习可以解决越来越复杂的问题
深度学习的历史大致可以分为三个阶段:1940-1960,这二十年间,主要是cybernetics(控制论)的发展;1980-1990,这十年间主要是connectionism发展;再其次就是自2006年以来deep Learning(深度学习)的发展,但是直到2016才在书中出现。 最早的一些学习算法是基于生物学习得到的,所以有了早期的ANN,下图是这几十年这个领域的发展趋势图深度学习并不是完全的模拟人脑,二十融合了线性代数、统计学、信息论、数值优化的等等。其实在这个领域,有人关注神经学,也有人不关注神经学。关注神经学的就成为计算神经学(computational neuroscience),是和深度学习不相同的研究领域,计算神经学主要关注怎么精确的模拟人脑的工作过程。 深度学习的第二阶段是1980s,主要是伴随着认知科学(cognitive science)的兴起。联接机制就是将大量的简单的计算单元用网络联接在一起,从而达到智能化的表现。这一阶段为当前的深度学习留下了一些核心的概念:分布式特征表达;反向传播算法;long short-term memory(LSTM)方法。 Kernel machines和graphical model 导致了神经网络的衰退直到2007年。 深度学习需要的是用一个单独的深度学习结构来解决多种不同的问题。2006年,Geoffrey Hinton展示了DBF,采用greedy layer-wise进行有效的训练。Dl的使用,不仅是用来强调可以训练比以前更深的网络,更是将注意力集中在了深度的理论重要性。 其他的还有数据的增加和有更多的计算资源导致的模型size的增加,提高准确定、复杂性和现实世界的影响。重要的是强化学习,通过尝试和失误,在不要人参与的前提下可以达到学习的目的,深度学习可以用来改善强化学习的能力。
深度学习是机器学习的一个分支,要想理解深度学习,必须对机器学习的概念有一个了解。 首先,说明什么是学习算法,举例:线性回归算法。很多的机器学习算法存在很多的hyperparameters,这些hyperparameters由算法的外部来决定,书中讨论了如何设置这些额外的参数。统计学中的两项重要统计理论:基于频率的估计和贝叶斯推理(frequentist estimators and Bayesian inference)。很多的深度学习算法是基于随机梯度下降方法。
学习算法
机器学习当中的学习指的是什么? “A computer program is said to learn from experience E with respect to some class of tasks T and performance measure P , if its performance at tasks in T , as measured by P, improves with experience E ”(Mitchell) 学习本身并不是机器学习的任务,机器学习的task是去完成任务。能用机器学习解决的task有: Classification, Classification with missing inputs, Regression,Transcription(例如光学字符识别),Machine translation,Structured output(例如语法分析,Anomaly detection,Synthesis and sampling,Imputation of missing values,Denoising(去噪声),Density estimation or probability mass function estimation 测量P就是来估计学习算法的能力。通常有估计算法的精度,算法的错误率来表示 或者 a continuous-valued score for each example,最常用的就是average log-probability。通常,可以根据一个学习方法在一个新的数据集上的效果来判断方法的好坏,这个数据集就是test set。监督和非监督的学习差别在于是不是需要进行label或者targets。可以将机器学习分为监督学习、非监督学习、半监督学习、多实例学习。 有一些的机器学习算法并不一定涉及到固定的数据集,类似强化学习(reinforcement learning)需要与环境进行交互,所以在学习过程和经验之间有一个反馈。常用的数据集(其实这个数据集就是experence)就是design matrix,设计矩阵,就是每一列包含不同的例子,每一列包含着不同的feature。但是这里需要注意,既然是采用矩阵,那么例子必须可以采用向量来描述才行。例子采用了线性回归的例子
Capacity, Overfitting and Underfitting
-能力,过拟合和欠拟合 机器学习最具有挑战的地方在于希望学习算法能够在面对新的、从未见过的数据上表现的很好。这种能力就被称作为泛化能力。训练数据和测试数据生成的过程称为 data generating distribution。随机选择的模型的期望训练误差和期望的测试误差相同,这就满足要求。所以机器学习方法的目标就是使训练误差尽量小,使测试误差和训练误差的gap尽量小,这两个目标与解决机器学习过程中的过拟合和欠拟合是一致的。合适的capacity才能是算法在解决问题的时候不出现过拟合和欠拟合,对于给出合适的capacity的方法:1.by changing the number of input features it has, and simultaneously adding new parameters associated with those features.改变特征的数量,同时添加与这些特征有关的新的参数。 增强机器学习的泛化能力,从很早就开始了,直到20世纪的统计学习理论,由万普尼克(Vapnik)建立的一套机器学习理论,使用统计的方法,因此有别于归纳学习等其它机器学习方法。由这套理论所引出的支持向量机对机器学习的理论界以及各个应用领域都有极大的贡献。统计学习理论为为机器学习算法提供了多种量化模型capacity的方式,最著名的就是Vapnik-Chervonenkis dimension(VC维(Vapnik-Chervonenkis Dimension)的概念是为了研究学习过程一致收敛的速度和推广性,由统计学理论定义的有关函数集学习性能的一个重要指标。传统的定义是:对一个指示函数集,如果存在H个样本能够被函数集中的函数按所有可能的2的H次方种形式分开,则称函数集能够把H个样本打散;函数集的VC维就是它能打散的最大样本数目H。若对任意数目的样本都有函数能将它们打散,则函数集的VC维是无穷大,有界实函数的VC维可以通过用一定的阈值将它转化成指示函数来定义),VC维的话表明了二态分类器的capacity。 但是深度学习模型的capacity特别困难是因为受到优化算法的capabilities受到限制,同时对于深度学习中的非凸优化问题缺乏理论上的理解。简单的函数能减小gap,但是还是需要选择复杂的假设来达到小的训练误差。为了达到capacity的极限值,引入非参数模型(non-parametric models)。一般情况下非参数模型在实际当中是不能实现的,但是依然可以设计理论上的非参数模型(非参数模型是指系统的数学模型中非显式地包含可估参数。例如,系统的频率响应、脉冲响应、阶跃响应等都是非参数模型。非参数模型通常以响应曲线或离散值形式表示。可以理解为,传递函数其实是一个系统的模型,但是这个传递函数并没有显性的包含这个系统的实际参数),举了nearest neighbor regression这个例子。
## The No Free Lunch Theorem
没有免费的午餐定理。大意上是说机器学习的方法不合逻辑,既然需要描述一组数据中的每一个成员就需要获得所有成员的信息,这个就不符合逻辑规则。机器学习采用了probabilistic rules来避免这个问题,概率论的方法就是找到一个成员probably正确,同时most成员都能接受。但是呢,任然没有解决这个问题,每个机器算法都会有误差,没有什么机器算法会比其他机器算法更加通用。但是这个问题只是说在面对所有all数据时,但是对于实际中特定的任务数据,这个还是可以设计出更加适合性能良好的方案。
Regularization 归一化
对于以上提到的问题,说明针对特定的问题需要设置特定的学习算法,但是呢,对于要解决的问题可以设置偏好的算法,当这个算法不好用时再采用其它的算法。例如对于线性回归可以采用weight decay(权值衰减)的方法,添加一个权值来调节线性回归的非线性能力。更通用的方法是给cost function 添加一个regularizer(正则化矩阵)用来调节学习函数模型(正则化中我们将保留所有的特征变量,但是会减小特征变量的数量级(参数数值的大小θ(j))。这个方法非常有效,当我们有很多特征变量时,其中每一个变量都能对预测产生一点影响。正如我们在房价预测的例子中看到的那样,我们可以有很多特征变量,其中每一个变量都是有用的,因此我们不希望把它们删掉,这就导致了正则化概念的发生。接下来我们会讨论怎样应用正则化和什么叫做正则化均值,然后将开始讨论怎样使用正则化来使学习算法正常工作,并避免过拟)
Hyperparameters and Validation Sets
超参数和验证集 大多数的机器学习算法用Hyperparameters 来控制算法的表现能力。如果只是在训练集上采用超参数进行学习,通常会导致 overfitting,这样就需要验证集来解决这个问题。通常用训练数据来构建验证集,将训练数据拆分成两个不相交的集合,一个作为训练集,另一个作为验证集。一般80%用作训练,20%用作验证。 交叉验证。数据集较小的时候可能就不好用了,所以能要采用交叉验证的方式,k-fold cross-validation procedure是一种比较常用的交叉验证的方式。
估计、偏差、方差
参数估计是解决泛化、欠拟合、过拟合的良好工具。
Point Estimation为一些关注的量提供"最好的"点估计。点估计的对象可以是一个参数、也可以是一个参数向量、也可以是整个函数。k-fold cross-validation algorithm为例讲解了点估计的方法。点估计(point estimation)是用样本统计量来估计总体参数,因为样本统计量为数轴上某一点值,估计的结果也以一个点的数值表示,所以称为点估计。点估计和区间估计属于总体参数估计问题。何为总体参数统计,当在研究中从样本获得一组数据后,如何通过这组信息,对总体特征进行估计,也就是如何从局部结果推论总体的情况,称为总体参数估计。估计方法:最大似然估计和最小二乘估计,贝叶斯估计最大似然估计此法作为一种重要而普遍的点估计法,由英国统计学家R.A.费希尔在1912年提出。后来在他1921年和1925年的工作中又加以发展;最小二乘估计这个重要的估计方法是由德国数学家C.F.高斯在1799~1809年和法国数学家A.-M.勒让德在1806年提出。Function Estimation实际上是点估计的扩展概念,当点估计用于估计输入和目标变量时就变成了Function Estimation. 前边的线性回归和多项式回归都是Function Estimation的例子。BiasBias(theta)=E(Estimation_theta)-theta.举例伯努利分布,高斯分布的均值估计,高斯分布的方差估计。当无偏差估计可取时,并不能说明这个是最好的,因为参数估计偏差通常会用作其他的处理。Variance and Standard ErrorTrading off Bias and Variance to Minimize Mean Squared Error误差和方差代表着估计当中误差的两个不同来源。偏差表征的是期望误差,方差表征的是对于任意的样本的期望误差的偏差。在面对两种方案,一种期望更大,另一种方差更大的情况,那么这个时候就要考虑交叉验证,需要计算mean squared error(MES)Consistency 一致收敛关注随着数据量的增长,参数估计的性能。通常希望,随着数据集的数据的增加,我们的估计值能够一直收敛到实际参数。
自动编码 Autoencoder
自动编码(autoencoder)是一种无监督的机器学习技术,利用神经网络产生的低维来代表高维输入。传统上,依靠线性降维方法,如主成分分析(PCA),找到最大方差在高维数据的方向。通过选择只有那些有最大方差的轴,主成分分析(PCA)的目的是捕获包含的大部分信息输入的方向,所以我们可以尽可能用最小数量的维度。主成分分析(PCA)的线性度然而限制了可以提取的特征维度。但是自动编码(Autoencoders)用固有的非线性神经网络克服了这些限制。 自动编码(autoencoder)由两个主要部分组成,编码器网络和译码器网络。编码器网络在训练和部署的时候被使用,而译码器网络只是在训练的时候使用。编码器网络的目的是找到一个给定的输入的压缩表示。在这个例子中,我们从2000 个维度的输入中生成了30个维度。译码器网络的目的只是一个编码器网络的反射,是重建原始输入尽可能密切。使用它在训练的目的是为了迫使自动编码(autoencoder)选择最丰富特征的压缩。自动编码器就是一种尽可能复现输入信号的神经网络。 采用这个方法构建多层的结构时,我们就通过调整encoder和decoder的参数,使得重构误差最小,这时候我们就得到了输入input信号的第一个表示了,也就是编码code了。那第二层和第一层的训练方式就没有差别了,我们将第一层输出的code当成第二层的输入信号,同样最小化重构误差,就会得到第二层的参数,并且得到第二层输入的code,也就是原输入信息的第二个表达了。注意,在确定了第一层的参数以后,就不需要再有decode了,以后每一层都是这样。到这里,这个AutoEncoder还不能用来分类数据,因为它还没有学习如何去连结一个输入和一个类。它只是学会了如何去重构或者复现它的输入而已。或者说,它只是学习获得了一个可以良好代表输入的特征,这个特征可以最大程度上代表原输入信号。那么,为了实现分类,我们就可以在AutoEncoder的最顶的编码层添加一个分类器(例如罗杰斯特回归、SVM等),然后通过标准的多层神经网络的监督训练方法(梯度下降法)去训练。可用的编码器有:Sparse AutoEncoder稀疏自动编码器,Denoising AutoEncoders降噪自动编码器,
稀疏编码
如果我们把输出必须和输入相等的限制放松,同时利用线性代数中基的概念,就是线性相关的表示。将输出用一些基和系数的运算表示,最小化残差表达式,再加上加上L1的Regularity限制来编码的方式称为稀疏编码。稀疏编码参考。稀疏编码是k-means算法的变体从最大似然到EM算法解析博客。
Restricted Boltzmann Machine (RBM)限制波尔兹曼机
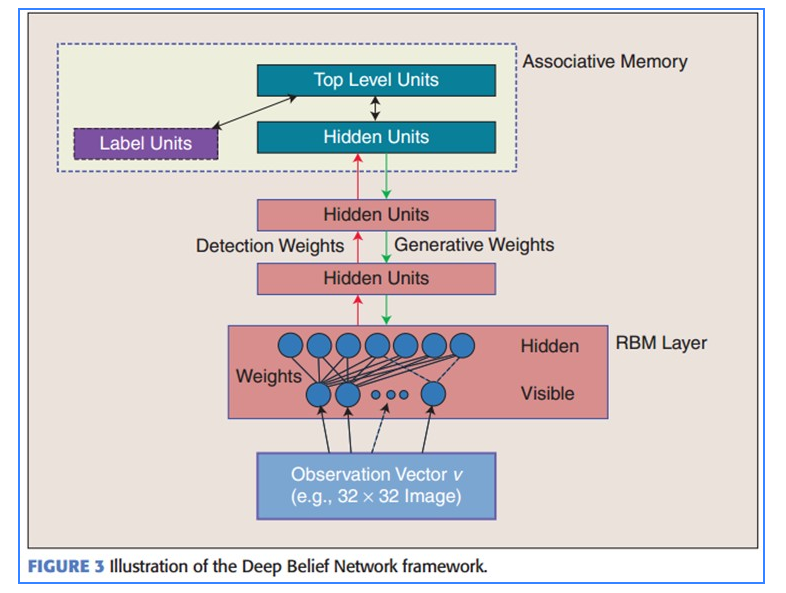
假设有一个二部图,每一层的节点之间没有链接,一层是可视层,即输入数据层(v),一层是隐藏层(h),如果假设所有的节点都是随机二值变量节点(只能取0或者1值),同时假设全概率分布p(v,h)满足Boltzmann 分布,我们称这个模型是Restricted BoltzmannMachine (RBM)。 首先,这个模型因为是二部图(二分图又称作二部图,是图论中的一种特殊模型。 设G=(V,E)是一个无向图,如果顶点V可分割为两个互不相交的子集(A,B),并且图中的每条边(i,j)所关联的两个顶点i和j分别属于这两个不同的顶点集(i in A,j in B),则称图G为一个二分图。),所以在已知v的情况下,所有的隐藏节点之间是条件独立的(因为节点之间不存在连接),即p(h|v)=p(h1|v)…p(hn|v)。同理,在已知隐藏层h的情况下,所有的可视节点都是条件独立的。同时又由于所有的v和h满足Boltzmann 分布,因此,当输入v的时候,通过p(h|v) 可以得到隐藏层h,而得到隐藏层h之后,通过p(v|h)又能得到可视层,通过调整参数,我们就是要使得从隐藏层得到的可视层v1与原来的可视层v如果一样,那么得到的隐藏层就是可视层另外一种表达,因此隐藏层可以作为可视层输入数据的特征,所以它就是一种Deep Learning方法。 如果,我们把隐藏层的层数增加,我们可以得到Deep Boltzmann Machine(DBM);如果我们在靠近可视层的部分使用贝叶斯信念网络(即有向图模型,当然这里依然限制层中节点之间没有链接),而在最远离可视层的部分使用Restricted Boltzmann Machine,我们可以得到DeepBelief Net(DBN)+
Deep Belief Networks深信度网络
DBNs是一个概率生成模型,与传统的判别模型的神经网络相对,生成模型是建立一个观察数据和标签之间的联合分布,对P(Observation|Label)和 P(Label|Observation)都做了评估,而判别模型仅仅而已评估了后者。 在训练过程中,首先将可视向量值映射给隐单元;然后可视单元由隐层单元重建;这些新可视单元再次映射给隐单元,这样就获取新的隐单元。执行这种反复步骤叫做吉布斯采样。
Convolutional Neural Networks卷积神经网络
它的权值共享网络结构使之更类似于生物神经网络,降低了网络模型的复杂度,减少了权值的数量。该优点在网络的输入是多维图像时表现的更为明显,使图像可以直接作为网络的输入,避免了传统识别算法中复杂的特征提取和数据重建过程。卷积网络是为识别二维形状而特殊设计的一个多层感知器,这种网络结构对平移、比例缩放、倾斜或者共他形式的变形具有高度不变性。CNNs是第一个真正成功训练多层网络结构的学习算法。 卷积神经网络是一个多层的神经网络,每层由多个二维平面组成,而每个平面由多个独立神经元组成。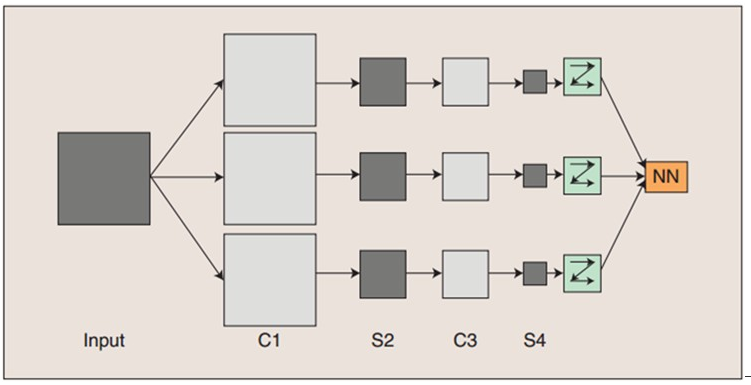 一般地,C层为特征提取层,每个神经元的输入与前一层的局部感受视野相连,并提取该局部的特征,一旦该局部特征被提取后,它与其他特征间的位置关系也随之确定下来;S层是特征映射层,网络的每个计算层由多个特征映射组成,每个特征映射为一个平面,平面上所有神经元的权值相等。特征映射结构采用影响函数核小的sigmoid函数作为卷积网络的激活函数,使得特征映射具有位移不变性。总之,卷积网络的核心思想是将:局部感受野、权值共享(或者权值复制)以及时间或空间亚采样这三种结构思想结合起来获得了某种程度的位移、尺度、形变不变性。
一般地,C层为特征提取层,每个神经元的输入与前一层的局部感受视野相连,并提取该局部的特征,一旦该局部特征被提取后,它与其他特征间的位置关系也随之确定下来;S层是特征映射层,网络的每个计算层由多个特征映射组成,每个特征映射为一个平面,平面上所有神经元的权值相等。特征映射结构采用影响函数核小的sigmoid函数作为卷积网络的激活函数,使得特征映射具有位移不变性。总之,卷积网络的核心思想是将:局部感受野、权值共享(或者权值复制)以及时间或空间亚采样这三种结构思想结合起来获得了某种程度的位移、尺度、形变不变性。
机器学习优化算法—L-BFGS
关于优化算法的求解,书上已经介绍了很多的方法,比如有梯度下降法,坐标下降法,牛顿法和拟牛顿法。梯度下降法是基于目标函数梯度的,算法的收敛速度是线性的,并且当问题是病态时或者问题规模较大时,收敛速度尤其慢(几乎不适用);坐标下降法虽然不用计算目标函数的梯度,但是其收敛速度依然很慢,因此它的适用范围也有局限;牛顿法是基于目标函数的二阶导数(海森矩阵)的,其收敛速度较快,迭代次数较少,尤其是在最优值附近时,收敛速度是二次的。但牛顿法的问题在于当海森矩阵稠密时,每次迭代的计算量比较大,因为每次都会计算目标函数的海森矩阵的逆,这样一来,当问题规模较大时,不仅计算量大(有时大到不可计算),而且需要的存储空间也多,因此牛顿法在面对海量数据时由于每一步迭代的开销巨大而变得不适用;拟牛顿法是在牛顿法的基础上引入了海森矩阵的近似矩阵,避免每次迭代都要计算海森矩阵的逆,拟牛顿法的收敛速度介于梯度下降法和牛顿法之间,是超线性的。拟牛顿法的问题也是当问题规模很大时,近似矩阵变得很稠密,在计算和存储上也有很大的开销,因此变得不实用。
另外需要注意的是,牛顿法在每次迭代时不能总是保证海森矩阵是正定的,一旦海森矩阵不是正定的,优化方向就会“跑偏”,从而使得牛顿法失效,也说明了牛顿法的鲁棒性较差。拟牛顿法用海森矩阵的逆矩阵来替代海森矩阵,虽然每次迭代不能保证是最优的优化方向,但是近似矩阵始终是正定的,因此算法总是朝着最优值的方向在搜索。 从上面的描述可以看出,很多优化算法在理论上有很好的结果,并且当优化问题的规模较小时,上面的任何算法都能够很好地解决问题。而在实际工程中,很多算法却失效了。比如说,在实际工程中,很多问题是病态的,这样一来,基于梯度的方法肯定会失效,即便迭代上千上万次也未必收敛到很好的结果;另外,当数据量大的时候,牛顿法和拟牛顿法需要保存矩阵的内存开销和计算矩阵的开销都很大,因此也会变得不适用。 L-BFGS算法就是对拟牛顿算法的一个改进。它的名字已经告诉我们它是基于拟牛顿法BFGS算法的改进。L-BFGS算法的基本思想是:算法只保存并利用最近m次迭代的曲率信息来构造海森矩阵的近似矩阵。
四 深度学习必知的框架
GitHub上其实还有很多不错的开源项目值得关注,首先我们推荐目前规模人气最高的TOP3:
一、Caffe。源自加州伯克利分校的Caffe被广泛应用,包括Pinterest这样的web大户。与TensorFlow一样,Caffe也是由C++开发,Caffe也是Google今年早些时候发布的DeepDream项目(可以识别喵星人的人工智能神经网络)的基础。
二、Theano。2008年诞生于蒙特利尔理工学院,Theano派生出了大量深度学习Python软件包,最著名的包括Blocks和Keras。
三、Torch。Torch诞生已经有十年之久,但是真正起势得益于去年Facebook开源了大量Torch的深度学习模块和扩展。Torch另外一个特殊之处是采用了不怎么流行的编程语言Lua(该语言曾被用来开发视频游戏)。
除了以上三个比较成熟知名的项目,还有很多有特色的深度学习开源框架也值得关注:
四、Brainstorm。来自瑞士人工智能实验室IDSIA的一个非常发展前景很不错的深度学习软件包,Brainstorm能够处理上百层的超级深度神经网络——所谓的公路网络Highway Networks。
五、Chainer。来自一个日本的深度学习创业公司Preferred Networks,今年6月发布的一个Python框架。Chainer的设计基于define by run原则,也就是说,该网络在运行中动态定义,而不是在启动时定义,这里有Chainer的详细文档。
六、Deeplearning4j。 顾名思义,Deeplearning4j是”forJava”的深度学习框架,也是首个商用级别的深度学习开源库。Deeplearning4j由创业公司Skymind于2014年6月发布,使用 Deeplearning4j的不乏埃森哲、雪弗兰、博斯咨询和IBM等明星企业。
DeepLearning4j是一个面向生产环境和商业应用的高成熟度深度学习开源库,可与Hadoop和Spark集成,即插即用,方便开发者在APP中快速集成深度学习功能,可应用于以下深度学习领域:
人脸/图像识别
语音搜索
语音转文字(Speech to text)
垃圾信息过滤(异常侦测)
电商欺诈侦测
七、Marvin。是普林斯顿大学视觉工作组新推出的C++框架。该团队还提供了一个文件用于将Caffe模型转化成语Marvin兼容的模式。
八、ConvNetJS。这是斯坦福大学博士生Andrej Karpathy开发浏览器插件,基于万能的JavaScript可以在你的游览器中训练神经网络。Karpathy还写了一个ConvNetJS的入门教程,以及一个简洁的浏览器演示项目。
九、MXNet。出自CXXNet、Minerva、Purine等项目的开发者之手,主要用C++编写。MXNet强调提高内存使用的效率,甚至能在智能手机上运行诸如图像识别等任务。
十、Neon。由创业公司Nervana Systems于今年五月开源,在某些基准测试中,由Python和Sass开发的Neon的测试成绩甚至要优于Caffeine、Torch和谷歌的TensorFlow。
深度学习领域的学术研究可以包含四部分:
优化(Optimization),泛化(Generalization),表达(Representation)以及应(Applications)。除了应用(Applications)之外每个部分又可以分成实践和理论两个方面。
优化(Optimization):深度学习的问题最后似乎总能变成优化问题,这个时候数值优化的方法就变得尤其重要。
从实践方面来说,现在最为推崇的方法依旧是随机梯度递减,这样一个极其简单的方法以其强悍的稳定性深受广大研究者的喜爱,而不同的人还会结合动量(momentum)、伪牛顿方法(Pseudo-Newton)以及自动步长等各种技巧。此外,深度学习模型优化过程的并行化也是一个非常热的点,近年在分布式系统的会议上相关论文也逐渐增多。
在理论方面,目前研究的比较清楚的还是凸优化(Convex Optimization),而对于非凸问题的理论还严重空缺,然而深度学习大多数有效的方法都是非凸的。现在有一些对深度学习常用模型及其目标函数的特性研究,期待能够发现非凸问题中局部最优解的相关规律。
泛化(Generalization):一个模型的泛化能力是指它在训练数据集上的误差是否能够接近所有可能测试数据误差的均值。泛化误差大致可以理解成测试数据集误差和训练数据集误差之差。在深度学习领域变流行之前,如何控制泛化误差一直是机器学习领域的主流问题。
从实践方面来说,之前许多人担心的深度神经网络泛化能力较差的问题,在现实使用中并没有表现得很明显。这一方面源于大数据时代样本巨大的数量,另一方面近年出现了一些新的在实践上比较有效的控制泛化误差(Regularization)的方法,比如Dropout和DropConnect,以及非常有效的数据扩增(Data Agumentation)技术。是否还有其它实践中会比较有效的泛化误差控制方法一直是研究者们的好奇点,比如是否可以通过博弈法避免过拟合,以及是否可以利用无标记(Unlabeled)样本来辅助泛化误差的控制。
从理论方面来说,深度学习的有效性使得PAC学习(Probably Approximately Correct Learning)相关的理论倍受质疑。这些理论无一例外地属于“上界的上界”的一个证明过程,而其本质无外乎各种集中不等式(Concentration Inequality)和复杂性度量(Complexity Measurement)的变种,因此它对深度学习模型有相当不切实际的估计。这不应该是泛函理论已经较为发达的当下出现的状况,因此下一步如何能够从理论上分析深度学习模型的泛化能力也会是一个有趣的问题。而这个研究可能还会牵涉表达(Representation,见下)的一些理论。
表达(Representation):这方面主要指的是深度学习模型和它要解决的问题之间的关系,比如给出一个设计好的深度学习模型,它适合表达什么样的问题,以及给定一个问题是否存在一个可以进行表达的深度学习模型。
这方面的实践主要是两个主流,一方面那些笃信无监督学习(Unsupervised Learning)可行性的研究者们一直在寻找更好的无监督学习目标及其评价方法,以使得机器能够自主进行表达学习变得可能。这实际上包括了受限波尔兹曼模型(Restricted Boltzmann Machine),稀疏编码(Sparse Coding)和自编码器(Auto-encoder)等。另一方面,面对实际问题的科学家们一直在凭借直觉设计深度学习模型的结构来解决这些问题。这方面出现了许多成功的例子,比如用于视觉和语音识别的卷积神经网络(Convolutional Neural Network),以及能够进行自我演绎的深度回归神经网络(Recurrent Neural Network)和会自主玩游戏的深度强化学习(Reinforcement Learning)模型。绝大多数的深度学习研究者都集中在这方面,而这些也恰恰能够带来最大的学术影响力。
然而,有关表达(Representation)的理论,除了从认知心理学和神经科学借用的一些启发之外,几乎是空白。这主要是因为是否能够存在表达的理论实际上依赖于具体的问题,而面对具体问题的时候目前唯一能做的事情就是去类比现实存在的智能体(人类)是如何解决这一问题的,并设计模型来将它归约为学习算法。我直觉上认为,终极的表达理论就像是拉普拉斯幽灵(Laplace’s Demon)一样,如果存在它便无所不知,也因此它的存在会产生矛盾,使得这一理论实际上只能无限逼近。
应用(Applications):深度学习的发展伴随着它对其它领域的革命过程。在过去的数年中,深度学习的应用能力几乎是一种“敢想就能成”的状态。这当然得益于现今各行各业丰富的数据集以及计算机计算能力的提升,同时也要归功于过去近三十年的领域经验。未来,深度学习将继续解决各种识别(Recognition)相关的问题,比如视觉(图像分类、分割,计算摄影学),语音(语音识别),自然语言(文本理解);同时,在能够演绎(Ability to Act)的方面如图像文字描述、语音合成、自动翻译、段落总结等也会逐渐出现突破,更可能协助寻找NP难(NP-Hard)问题在限定输入集之后的可行算法。所有的这些都可能是非常好的研究点,能够带来经济和学术双重的利益。
深度学习数据集
*先来个不能错过的数据集网站(深度学习者的福音):*
http://deeplearning.net/datasets/**
首先说说几个收集数据集的网站:
1、Public Data Sets on Amazon Web Services (AWS)
http://aws.amazon.com/datasets
Amazon从2008年开始就为开发者提供几十TB的开发数据。
2、Yahoo! Webscope
http://webscope.sandbox.yahoo.com/index.php
3、Konect is a collection of network datasets
http://konect.uni-koblenz.de/
4、Stanford Large Network Dataset Collection
http://snap.stanford.edu/data/index.html
再就是说说几个跟互联网有关的数据集:
1、Dataset for “Statistics and Social Network of YouTube Videos”
http://netsg.cs.sfu.ca/youtubedata/
2、1998 World Cup Web Site Access Logs
http://ita.ee.lbl.gov/html/contrib/WorldCup.html
这个是1998年世界杯期间的数据集。从1998/04/26 到 1998/07/26 的92天中,发生了 1,352,804,107次请求。
3、Page view statistics for Wikimedia projects
http://dammit.lt/wikistats/
4、AOL Search Query Logs - RP
http://www.researchpipeline.com/mediawiki/index.php?title=AOL_Search_Query_Logs
5、livedoor gourmet
http://blog.livedoor.jp/techblog/archives/65836960.html
海量图像数据集:
1、ImageNet
http://www.image-net.org/
包含1400万的图像。
2、Tiny Images Dataset
http://horatio.cs.nyu.edu/mit/tiny/data/index.html
包含8000万的32x32图像。
3、 MirFlickr1M
http://press.liacs.nl/mirflickr/
Flickr中的100万的图像集。
4、 CoPhIR
http://cophir.isti.cnr.it/whatis.html
Flickr中的1亿600万的图像
5、SBU captioned photo dataset
http://dsl1.cewit.stonybrook.edu/~vicente/sbucaptions/
Flickr中的100万的图像集。
6、Large-Scale Image Annotation using Visual Synset(ICCV 2011)
http://cpl.cc.gatech.edu/projects/VisualSynset/
包含2亿图像
7、NUS-WIDE
http://lms.comp.nus.edu.sg/research/NUS-WIDE.htm
Flickr中的27万的图像集。
8、SUN dataset
http://people.csail.mit.edu/jxiao/SUN/
包含13万的图像
9、MSRA-MM
http://research.microsoft.com/en-us/projects/msrammdata/
包含100万的图像,23000视频
10、TRECVID
http://trecvid.nist.gov/
截止目前好像还没有国内的企业或者组织开放自己的数据集。希望也能有企业开发自己的数据集给研究人员使用,从而推动海量数据处理在国内的发展!
2014/07/07 雅虎发布超大Flickr数据集 1亿的图片+视频
http://yahoolabs.tumblr.com/post/89783581601/one-hundred-million-creative-commons-flickr-images-for
100多个有趣的数据集
http://www.csdn.net/article/2014-06-06/2820111-100-Interesting-Data-Sets-for-Statistics
视频人体姿态数据集
1. Weizmann 人体行为库
数据库一共包括90段视频,这些视频分别是由9个人执行了10个不同的动作(bend, jack, jump, pjump, run, side, skip, walk, wave1,wave2)。视频的背景,视角以及摄像头都是静止的。而且该数据库提供标注好的前景轮廓视频。不过此数据库的正确率已经达到100%了。下载地址:http://www.wisdom.weizmann.ac.il/~vision/SpaceTimeActions.html
2. KTH人体行为数据库
该数据库包括6类行为(walking, jogging, running, boxing, hand waving, hand clapping),是由25个不同的人执行的,分别在四个场景下,一共有599段视频。背景相对静止,除了镜头的拉近拉远,摄像机的运动比较轻微。这个数据库是现在的benchmark,正确率需要达到95.5%以上才能够发文章。下载地址:http://www.nada.kth.se/cvap/actions/
3. INRIA XMAX多视角视频库
该数据库从五个视角获得,一共11个人执行14种行为。室内四个方向和头顶一共安装5个摄像头。另外背景和光照基本不变。下载地址:http://4drepository.inrialpes.fr/public/viewgroup/6
4. UCF Sports 数据库
该视频包括150段关于体育的视频,一共有13个动作。实验室采用留一交叉验证法。2011年cvpr有几篇都用这个数据库,正确率要达到87%才能发文章。下载地址:http://vision.eecs.ucf.edu/data.html
6. Olympic sports dataset
该数据库有16种行为,783段视频。现在的正确率大约在75%左右。下载地址:http://vision.stanford.edu/Datasets/OlympicSports/
UCI收集的机器学习数据集
ftp://pami.sjtu.edu.cn
http://www.ics.uci.edu/~mlearn/\MLRepository.htm
样本数据库
http://kdd.ics.uci.edu/
http://www.ics.uci.edu/~mlearn/MLRepository.html
CASIA WebFace Database
中科院自动化研究所的几种数据集,里面包含掌纹,手写体,人体动作等6种数据集;需要按照说明申请,免费使用。
http://www.cbsr.ia.ac.cn/english/CASIA-WebFace-Database.html
微软人体姿态数据库 MSRC-12 Gesture Dataset
手势数据集
http://www.datatang.com/data/46521
备注:数据堂链接:http://www.datatang.com/
文本分类数据集
一个数据集是可以用的,即rainbow的数据集
http://www-2.cs.cmu.edu/afs/cs/p… ww/naive-bayes.html
其余杂数据集
癌症基因:
http://www.broad.mit.edu/cgi-bin/cancer/datasets.cgi
金融数据:
http://lisp.vse.cz/pkdd99/Challenge/chall.htm
各种数据集:
http://kdd.ics.uci.edu/summary.data.type.html
http://www.mlnet.org/cgi-bin/mlnetois.pl/?File=datasets.html
http://lib.stat.cmu.edu/datasets/
http://dctc.sjtu.edu.cn/adaptive/datasets/
http://fimi.cs.helsinki.fi/data/
http://www.almaden.ibm.com/software/quest/Resources/index.shtml
http://miles.cnuce.cnr.it/~palmeri/datam/DCI/