在高维数据处理中,为了简化计算量以及储存空间,需要对这些高维数据进行一定程度上的降维,并尽量保证数据的不失真。PCA和ICA是两种常用的降维方法。
PCA:principal component analysis ,主成分分析
ICA :Independent component analysis,独立成分分析
PCA,ICA都是统计理论当中的概念,在机器学习 当中应用很广,比如图像,语音,通信的分析处理。
从线性代数的角度去理解,PCA和ICA都是要找到一组基,这组基张成一个特征空间,数据的处理就都需要映射到新空间中去。
两者常用于机器学习中提取特征后的降维操作
ICA是找出构成信号的相互独立部分(不需要正交),对应高阶统计量分析。ICA理论认为用来观测的混合数据阵X是由独立元S经过A线性加权获得。ICA理论的目标就是通过X求得一个分离矩阵W,使得W作用在X上所获得的信号Y是独立源S的最优逼近,该关系可以通过下式表示:
Y = WX = WAS , A = inv(W)
ICA相比与PCA更能刻画变量的随机统计特性,且能抑制高斯噪声。
1. 问题:
1、PCA是一种数据降维的方法,但是只对符合高斯分布的样本点比较有效,那么对于其他分布的样本,有没有主元分解的方法呢?
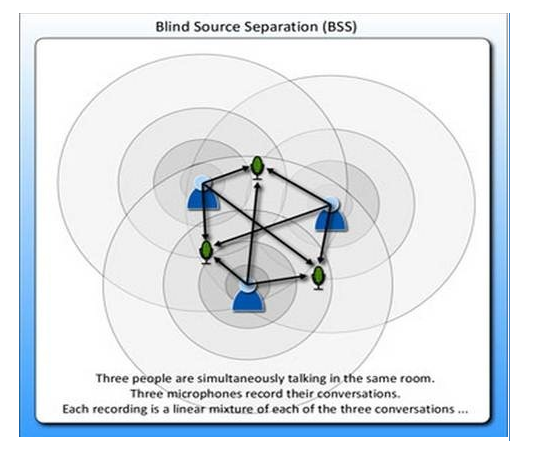
2、经典的鸡尾酒宴会问题(cocktail party problem)。假设在party中有n个人,他们可以同时说话,我们也在房间中一些角落里共放置了n个声音接收器(Microphone)用来记录声音。宴会过后,我们从n个麦克风中得到了一组数据x ( i ) ( x 1 ( i ) , x 2 ( i ) , . . . . x n ( i ) ) ; i = 1 , . . . , m x^{(i)}(x_1^{(i)},x_2^{(i)},....x_n^{(i)});i=1,...,m x ( i ) ( x 1 ( i ) , x 2 ( i ) , . . . . x n ( i ) ) ; i = 1 , . . . , m
将第二个问题细化一下,有n个信号源s ( s 1 , s 2 , . . . . , s n ) T , s ∈ R n s(s_1,s_2,....,s_n)^T,\;s \in R^n s ( s 1 , s 2 , . . . . , s n ) T , s ∈ R n
x = A s x = As x = A s
x的意义在上文解释过,这里的x不是一个向量,是一个矩阵。其中每个列向量是x ( i ) x^{(i)} x ( i ) x ( i ) = A s ( i ) x^{(i)}=As^{(i)} x ( i ) = A s ( i )
表示成图就是
这张图来自
http://amouraux.webnode.com/research-interests/research-interests-erp-analysis/blind-source-separation-bss-of-erps-using-independent-component-analysis-ica/
x ( i ) x^{(i)} x ( i ) s ( i ) s^{(i)} s ( i )
令W = A − 1 W=A^{-1} W = A − 1 s ( i ) = A − 1 x ( i ) = W x ( i ) s^{(i)}=A^{-1}x^{(i)}=Wx^{(i)} s ( i ) = A − 1 x ( i ) = W x ( i )
将W表示成
W = [ . . . w 1 T . . . . . . . . . . . . . w n T . . . ] W=\begin{bmatrix}
...w_1^T...\\
.......\\
...w_n^T...\end{bmatrix} W = ⎣ ⎡ . . . w 1 T . . . . . . . . . . . . . w n T . . . ⎦ ⎤
其中w i ∈ R n w_i \in R^n w i ∈ R n w i w_i w i
s j ( i ) = w j T x ( i ) s_j^{(i)}=w_j^Tx^{(i)} s j ( i ) = w j T x ( i )
2. ICA的不确定性(ICA ambiguities)
由于w和s都不确定,那么在没有先验知识的情况下,无法同时确定这两个相关参数。比如上面的公式s=wx。当w扩大两倍时,s只需要同时扩大两倍即可,等式仍然满足,因此无法得到唯一的s。同时如果将人的编号打乱,变成另外一个顺序,如上图的蓝色节点的编号变为3,2,1,那么只需要调换A的列向量顺序即可,因此也无法单独确定s。这两种情况称为原信号不确定。
图 1.8.2.1 - clip\_image052 令R是正交阵R R T = R T R = I RR^T=R^TR=I R R T = R T R = I A ′ = A R A^{'}=AR A ′ = A R x ′ = A ′ s x^{'}=A^{'}s x ′ = A ′ s E [ x ′ ( x ′ ) T ] = E [ A ′ s s T ( A ′ ) T ] = E [ A R s s T ( A R ) T ] = A R R T A T = A A T E[x^{'}(x^{'})^T]=E[A^{'}ss^T(A^{'})^T]=E[ARss^T(AR)^T]=ARR^TA^T=AA^T E [ x ′ ( x ′ ) T ] = E [ A ′ s s T ( A ′ ) T ] = E [ A R s s T ( A R ) T ] = A R R T A T = A A T
因此,不管混合矩阵是A还是A’,x的分布情况是一样的,那么就无法确定混合矩阵,也就无法确定原信号。
3. 密度函数和线性变换
在讨论ICA具体算法之前,我们先来回顾一下概率和线性代数里的知识。
假设我们的随机变量s有概率密度函数P s ( s ) P_s(s) P s ( s ) P x P_x P x P x P_x P x
令W = A − 1 W=A^{-1} W = A − 1 s = W x s=Wx s = W x p x ( x ) = p s ( W s ) p_x(x)=p_s(Ws) p x ( x ) = p s ( W s ) s ∼ U n i f o r m [ 0 , 1 ] s \sim Uniform[0,1] s ∼ U n i f o r m [ 0 , 1 ] p s ( s ) = 1 { 0 < = s < = 1 } p_s(s)=1 \{0<=s<=1\} p s ( s ) = 1 { 0 < = s < = 1 } p x ( x ) = 0 . 5 p_x(x)=0.5 p x ( x ) = 0 . 5 p x ( x ) = p s ( 0 . 5 s ) = 1 p_x(x)=p_s(0.5s)=1 p x ( x ) = p s ( 0 . 5 s ) = 1
p x ( x ) = p s ( W s ) ∣ W ∣ p_x(x)=p_s(Ws)|W| p x ( x ) = p s ( W s ) ∣ W ∣
推导方法f
F x ( x ) = P ( X < = x ) = P ( A S < = x ) = P ( S < = W x ) = F s ( W x ) F_x(x)=P(X<=x)=P(AS<=x)=P(S<=Wx)=F_s(Wx) F x ( x ) = P ( X < = x ) = P ( A S < = x ) = P ( S < = W x ) = F s ( W x )
p x ( x ) = F x ′ ( x ) = F s , ( W x ) = p s ( W x ) ∣ W ∣ p_x(x)=F_x^{'}(x)=F_s^{,}(Wx)=p_s(Wx)|W| p x ( x ) = F x ′ ( x ) = F s , ( W x ) = p s ( W x ) ∣ W ∣
更一般地,如果s是向量,A可逆的方阵,那么上式子仍然成立。
4. ICA算法
ICA算法归功于Bell和Sejnowski,这里使用最大似然估计来解释算法,原始的论文中使用的是一个复杂的方法Infomax principal。
图 1.8.2.2 - clip\_image086 p ( s ) = ∏ i = 1 n p s ( s i ) p(s)=\prod_{i=1}^{n}p_s(s_i) p ( s ) = ∏ i = 1 n p s ( s i )
这个公式代表一个假设前提:每个人发出的声音信号各自独立。有了p(s),我们可以求得p(x)
p ( x ) = p s ( W x ) ∣ W ∣ = ∣ W ∣ ∏ i = 1 n p s ( w i T x ) p(x)=p_s(Wx)|W|=|W|\prod_{i=1}^{n}p_s(w_i^Tx) p ( x ) = p s ( W x ) ∣ W ∣ = ∣ W ∣ ∏ i = 1 n p s ( w i T x )
左边是每个采样信号x(n维向量)的概率,右边是每个原信号概率的乘积的|W|倍。
前面提到过,如果没有先验知识,我们无法求得W和s。因此我们需要知道p s ( s i ) p_s(s_i) p s ( s i )
g ( s ) = 1 1 + e − s g(s)= \frac {1} {1+e^{-s}} g ( s ) = 1 + e − s 1
求导后
p s ( s ) = g ′ ( s ) = e s ( 1 + e s ) 2 p_s(s)=g^{'}(s)=\frac {e^s} {(1+e^s)^2} p s ( s ) = g ′ ( s ) = ( 1 + e s ) 2 e s
这就是s的密度函数。这里s是实数。
如果我们预先知道s的分布函数,那就不用假设了,但是在缺失的情况下,sigmoid函数能够在大多数问题上取得不错的效果。由于上式中p s ( s ) p_s(s) p s ( s )
知道了p s ( s ) p_s(s) p s ( s ) x ( i ) ( x 1 ( i ) , x 2 ( i ) , . . . . x n ( i ) ) ; i = 1 , . . . , m x^{(i)}(x_1^{(i)},x_2^{(i)},....x_n^{(i)});i=1,...,m x ( i ) ( x 1 ( i ) , x 2 ( i ) , . . . . x n ( i ) ) ; i = 1 , . . . , m
使用前面得到的x的概率密度函数,得
l ( W ) = ∑ i = 1 m ( ∑ j = 1 n l o g g ′ ( w j T x ( i ) ) + l o g ∣ W ∣ ) l(W)=\sum_{i=1}^{m}(\sum_{j=1}^{n}log \;g^{'}(w_j^Tx^{(i)})+log|W|) l ( W ) = ∑ i = 1 m ( ∑ j = 1 n l o g g ′ ( w j T x ( i ) ) + l o g ∣ W ∣ )
大括号里面是p ( x ( i ) ) p(x^{(i)}) p ( x ( i ) )
接下来就是对W求导了,这里牵涉一个问题是对行列式|W|进行求导的方法,属于矩阵微积分。这里先给出结果,在文章最后再给出推导公式。
▽ w ∣ W ∣ = ∣ W ∣ ( W − 1 ) T \bigtriangledown _w|W|=|W|(W^{-1})^T ▽ w ∣ W ∣ = ∣ W ∣ ( W − 1 ) T
最终得到的求导后公式如下,l o g g ′ ( s ) logg^{'}(s) l o g g ′ ( s ) 1 − 2 g ( s ) 1-2g(s) 1 − 2 g ( s )
图 1.8.2.4 - clip\_image110 图 1.8.2.5 - clip\_image112 当迭代求出W后,便可得到s ( i ) = W x ( i ) s^{(i)}=Wx^{(i)} s ( i ) = W x ( i )
注意: 我们计算最大似然估计时,假设了x ( i ) x^{(i)} x ( i ) y ( i ) y^{(i)} y ( i )
回顾一下鸡尾酒宴会问题,s是人发出的信号,是连续值,不同时间点的s不同,每个人发出的信号之间独立(s i s_i s i s j s_j s j
5. 实例
图 1.8.2.6 - clip\_image122 s=2时的原始信号
图 1.8.2.7 - clip\_image124 观察到的x信号
图 1.8.2.8 - clip\_image126 使用ICA还原后的s信号
6. 行列式的梯度
对行列式求导,设矩阵A是n×n的,我们知道行列式与代数余子式有关,
∣ A ∣ = ∑ i = 1 n ( − 1 ) i + j A i j ∣ A i j ∣ ( f o r a n y j ∈ 1 , . . . n ) |A|=\sum_{i=1}^{n}(-1)^{i+j}A_{ij}|A_{ij}| (for \;\; any \;\;j \in 1,...n) ∣ A ∣ = ∑ i = 1 n ( − 1 ) i + j A i j ∣ A i j ∣ ( f o r a n y j ∈ 1 , . . . n )
A i j A_{ij} A i j A k l A_{kl} A k l
∂ ∂ A k l ∣ A ∣ = ∂ ∂ A k l ∑ i = 1 n ( − 1 ) i + j A i j ∣ A i j = ( − 1 ) k + l ∣ A k l ∣ = ( a d j ( A ) ) l k \frac{\partial }{\partial A_{kl}}|A|=\frac{\partial }{\partial A_{kl}}\sum_{i=1}^{n}(-1)^{i+j}A_{ij}|A_{ij}=(-1)^{k+l}|A_{kl}|=(adj(A))_{lk} ∂ A k l ∂ ∣ A ∣ = ∂ A k l ∂ ∑ i = 1 n ( − 1 ) i + j A i j ∣ A i j = ( − 1 ) k + l ∣ A k l ∣ = ( a d j ( A ) ) l k
adj(A)跟我们线性代数中学的A ∗ A^{*} A ∗
▽ A ∣ A ∣ = ( a d j ( A ) ) T = ∣ A ∣ A − T \triangledown_A|A|=(adj(A))^T=|A|A^{-T} ▽ A ∣ A ∣ = ( a d j ( A ) ) T = ∣ A ∣ A − T