随时间反向传播(BPTT)算法
先简单回顾一下RNN的基本公式:
st=tanh(Uxt+Wst−1)
y^t=softmax(Vst)
RNN的损失函数定义为交叉熵损失:
Et(yt,y^t)=−ytlogy^t
E(y,y^)=∑tEt(yt,y^t)=−∑tytlogy^t
yt是时刻t的样本实际值, y^_t是预测值,我们通常把整个序列作为一个训练样本,所以总的误差就是每一步的误差的加和。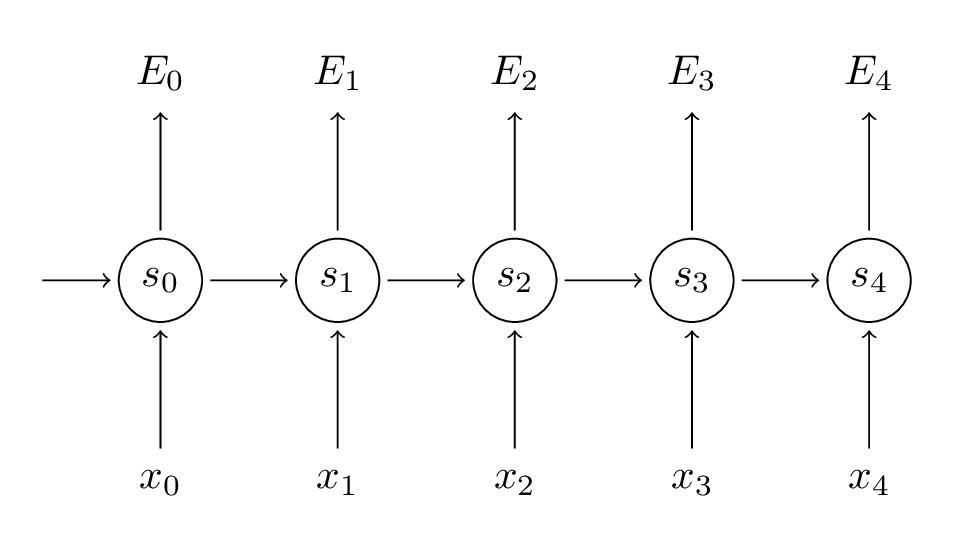 我们的目标是计算损失函数的梯度,然后通过梯度下降方法学习出所有的参数U, V, W。比如:∂W∂E=∑t∂W∂Et
我们的目标是计算损失函数的梯度,然后通过梯度下降方法学习出所有的参数U, V, W。比如:∂W∂E=∑t∂W∂Et
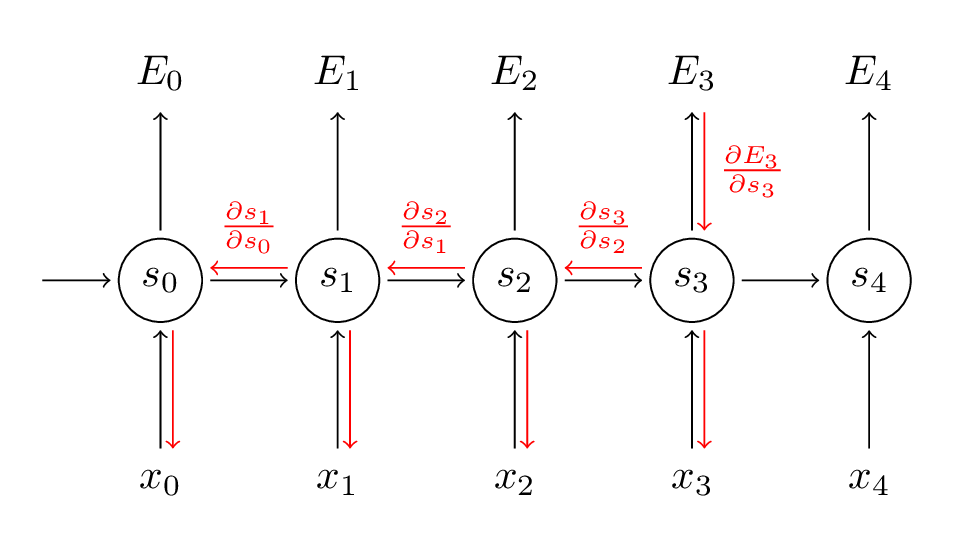 为了更好理解BPTT我们来推导一下公式:
为了更好理解BPTT我们来推导一下公式:
前向 前向传播1:
a0=x0∗u
b0=s−1∗w
z0=a0+b0+k
s0=func(z0) (func 是 sig或者tanh)
前向 前向传播2:
a1=x1∗u
b1=s0∗w
z1=a1+b1+k
s1=func(z1)(func 是 sig 或者tanh)
q=s1∗v1
zt=u∗xt+w∗st−1+k
st=func(zt)
输出 层:
o=func(q)(func 是 softmax)
E=func(o)(func 是 x-entropy)
下面 是U的推导
∂E/∂u=∂E/∂u1+∂E/∂u0
∂E/∂u1=∂E/∂o∗∂o/∂q∗∂q/∂s1∗∂s1/∂z1∗∂z1/∂a1∗∂a1/∂u1
∂E/∂u0=∂E/∂o∗∂o/∂q∗∂q/∂s1∗∂s1/∂z1∗∂z1/∂b1∗∂b1/∂s0∗∂s0/dz0∗∂z0/∂a0∗∂a0/∂u0
∂E/∂u=∂E/∂o∗∂o/∂q∗v1∗∂s1/∂z1∗((1∗x1)+(1∗w1∗∂s0/∂z0∗1∗x0))
∂E/∂u=∂E/∂o∗∂o/∂q∗v1∗∂s1/∂z1∗(x1+w1∗∂s0/∂z0∗x0)
W参数的推导如下
∂E/∂w=∂E/∂o∗∂o/∂q∗v1∗∂s1/∂z1∗(s0+w1∗∂s0/∂z0∗s−1)
总结
∂u∂L=∑t∂ut∂L=∂o∂L∂s1∂o∂u1∂s1+∂o∂L∂s1∂o∂s0∂s1∂u0∂s0
∂w∂L=∑t∂wt∂L=∂o∂L∂s1∂o∂w1∂s1+∂o∂L∂s1∂o∂s0∂s1∂w0∂s0
xt是时间t的输入
 图 1.28.4.1 - Many-to-one RNN
图 1.28.4.1 - Many-to-one RNN
更多了解RNN,推荐Goodfellow et al RNN chapter和Andrej Karpathy minimal character RNN实现。